TL;DR: We present Flash-GRPO, a single-step training framework that outperforms full trajectory training in alignment quality under low computational budgets while substantially improving training efficiency.
Wan2.1-1.3B
Flash-GRPO
Prompt: Marvel superhero Iron Man flying high in the sky, amidst a clear blue cloudless day. Tony Stark, wearing his iconic red, gold, and black armor, pilots the Iron Man suit effortlessly. His sleek helmet reflects the sunlight, and his glowing red eyes scan the horizon. Flying at an altitude of over 10,000 feet, he performs acrobatic maneuvers, twisting and turning gracefully. The Iron Man suit’s thrusters emit a soft humming sound as it glides smoothly. The background showcases vast, unobstructed skies dotted with fluffy white clouds. In the distance, a few birds fly by, adding life to the serene landscape. Iron Man maintains a calm and focused expression, ready for any challenge. The shot captures him from above, showcasing the intricate design and movement of his suit. Dynamic aerial perspective, fast-paced camera movements, and sweeping shots reveal the beauty and power of Iron Man’s flight.
Wan2.1-1.3B
Flash-GRPO
Prompt: A vintage steam train slowly moving along a winding mountain track. The train is painted in faded red and black colors, with steam billowing out from its chimney. The landscape is covered in snow-capped peaks and lush greenery. Trees sway gently in the wind, their branches touching the sides of the train. The carriage interiors are dimly lit, with wooden panels and brass fittings. Passengers inside, bundled up in woolen coats and hats, sit quietly, some reading newspapers, others sleeping. The camera captures the train as it steadily climbs the mountain, capturing the steam rising into the crisp mountain air. The background features a serene, snowy mountain range with a few distant villages nestled at the base. Low-angle shot, medium shot of the train partially visible.
Wan2.1-1.3B
Flash-GRPO
Prompt: A gentle scene captured in soft focus, a fluffy white kitten with oversized green eyes and tufted ears sits contentedly on a woven basket. The kitten’s fur is a mix of soft gray and creamy white, with occasional specks of black. It wears a small, cozy brown collar adorned with a tiny bell. The kitten is surrounded by a variety of colorful cat treats scattered in a ceramic bowl on a wooden table. The bowl is filled with wet food, partially consumed, with bits of kibble still visible. The kitten’s tail curls gently as it eats, occasionally batting at stray crumbs with its paw. The background is a softly lit room, with soft shadows highlighting the textures of the furniture and floor. A window behind the scene shows a sunny afternoon outside. The scene is captured with a warm, nostalgic feel, reminiscent of old family photos. Soft focus, medium shot, half-body view.
Abstract
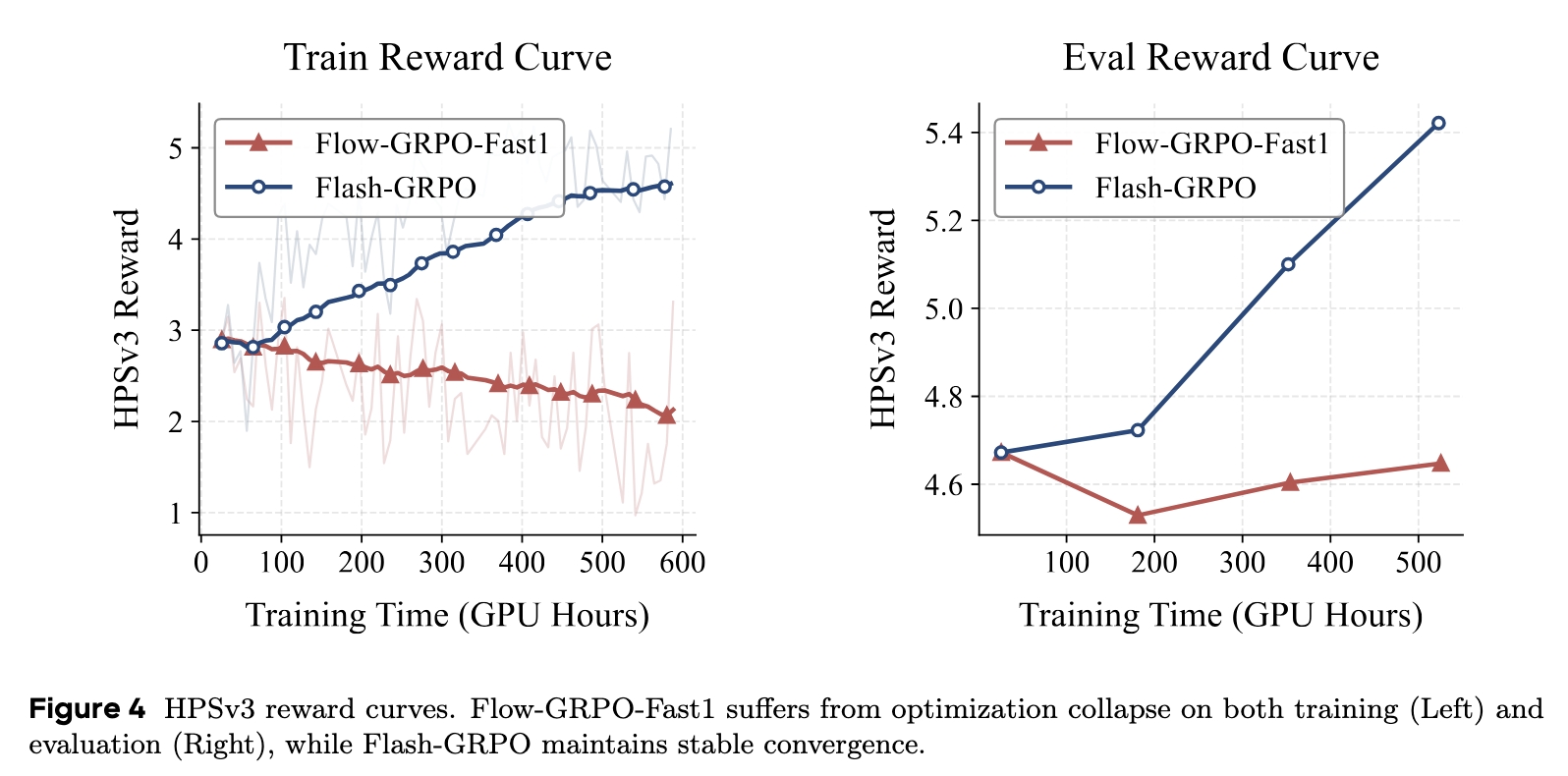
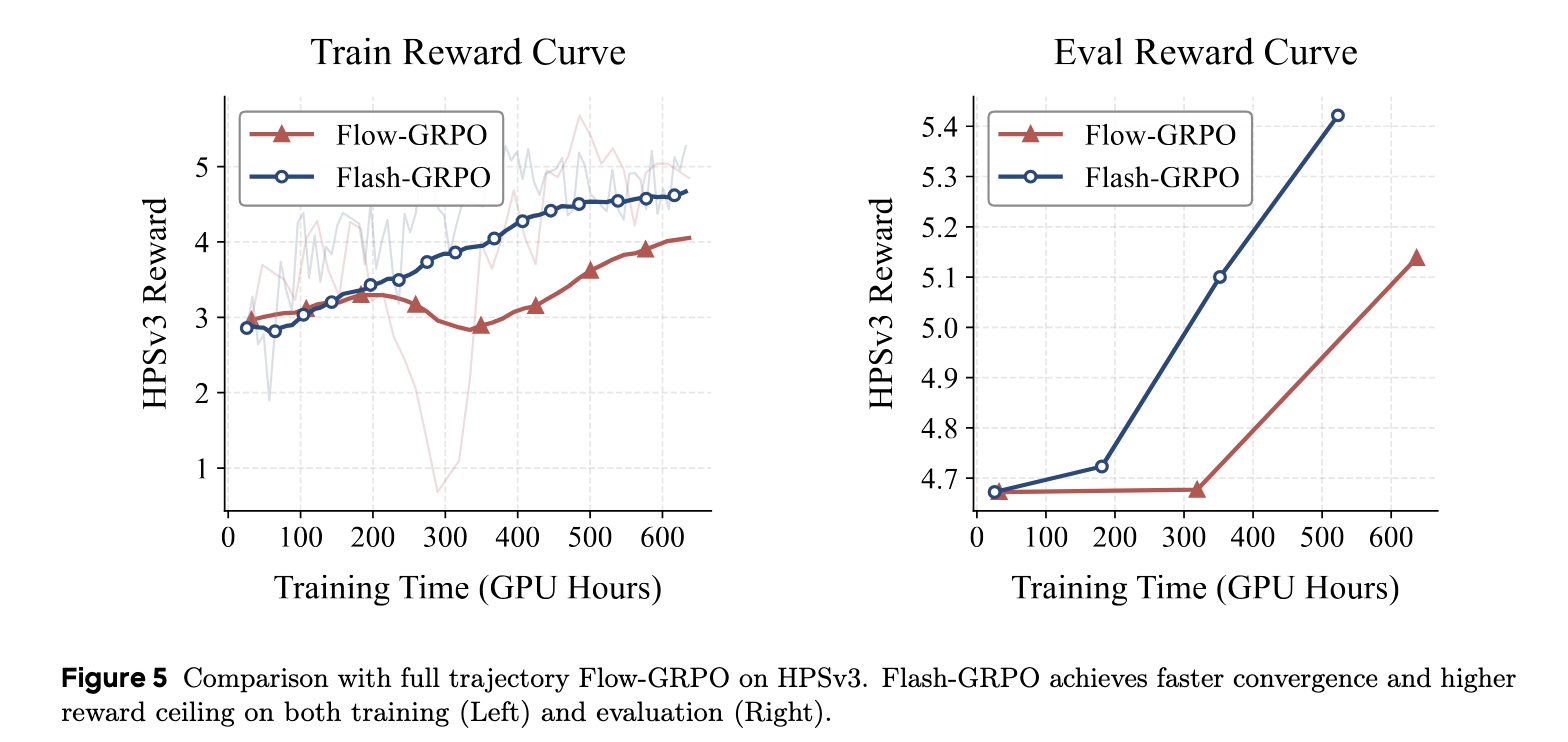
Group Relative Policy Optimization has emerged as essential for aligning video diffusion models with human preferences, but faces a critical computational bottleneck: training a 14B parametered model typically demands hundreds of GPU days per experiment. Existing efficiency methods reduce costs through sliding window subsampling training timesteps, but fundamentally compromise optimization, exhibiting severe instability and failing to reach full trajectory performance. We present Flash-GRPO, a single-step training framework that outperforms full trajectory training in alignment quality under low computational budgets while substantially improving training efficiency. Flash-GRPO addresses two critical challenges: iso-temporal grouping eliminates timestep- confounded variance by enforcing prompt-wise temporal consistency, decoupling policy performance from timestep difficulty; temporal gradient rectification neutralizes the time-dependent scaling factor that causes vastly inconsistent gradient magnitudes across timesteps. Experiments on 1.3B to 14B parameter models validate Flash-GRPO’s effectiveness, demonstrating substantial training acceleration with consistent stability and state-of-the-art alignment quality.
Method
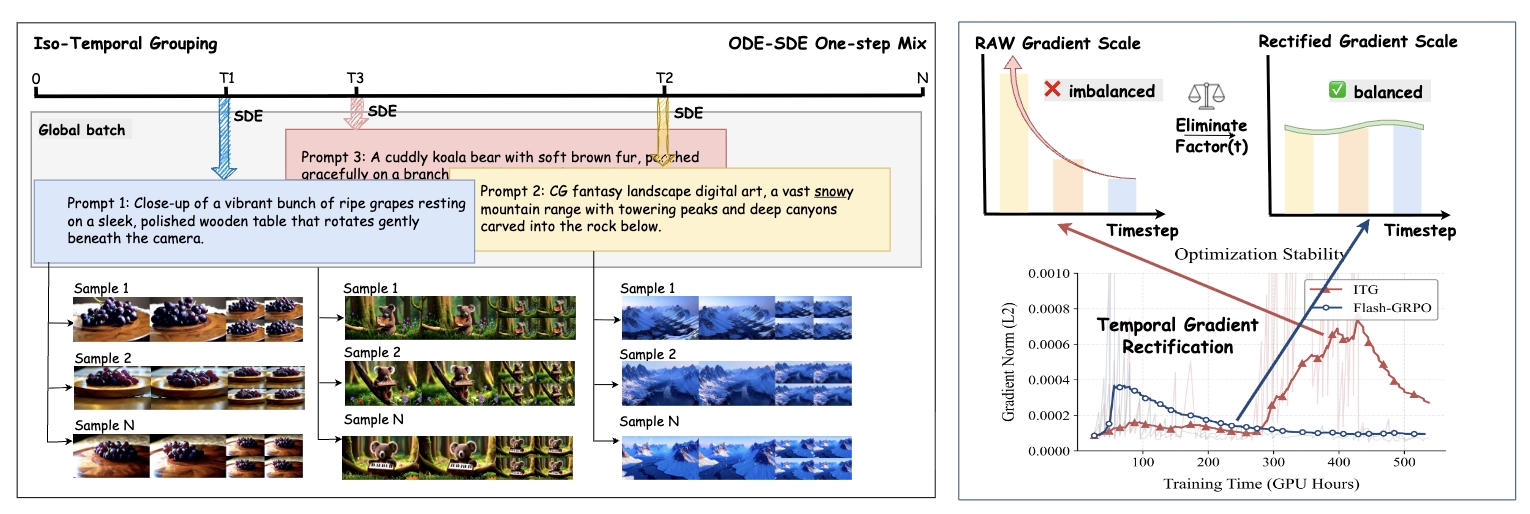
Overview of the Flash-GRPO Framework. Left: Iso-temporal Grouping: each prompt performs ODE-to-SDE transition at a single sampled timestep for exploration and gradient computation, while other timesteps use deterministic ODE for accurate reward signals. Rollouts within each group share this transition timestep but differ in initial noise, factorizing policy-induced variance from timestep-induced variance. Right: Temporal Gradient Rectification: the SDE discretization introduces a time-dependent scaling factor λ(t) that causes gradient magnitudes to vary by orders of magnitude. Normalizing by 1/λ(t) ensures uniform contribution across timesteps, eliminating discretization-induced optimization bias.
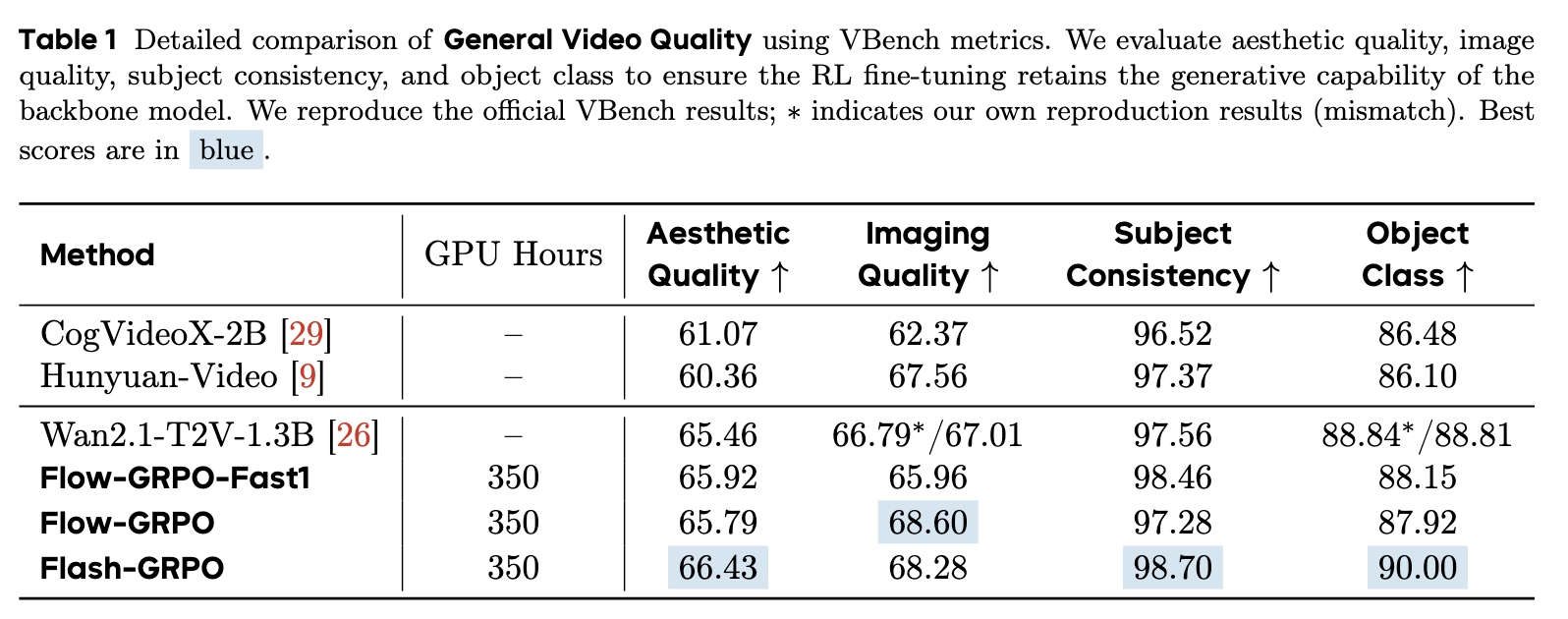
Comparisons
Visualization
Wan2.1-1.3B
Flash-GRPO
Wan2.1-1.3B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO
Wan2.1-14B
Flash-GRPO